What's in your weed? You might be surprised PLOSONE
To evaluate the difference between the labeling methods described above, silhouette scores were calculated on the full dataset for the three different methods. Welch’s t-tests and effect sizes were calculated between these methods. Statistical significance was evaluated after using the Bonferroni correction for three multiple comparisons.] was run on the terpene data of THC-dominant samples and color coded by k-means cluster label.
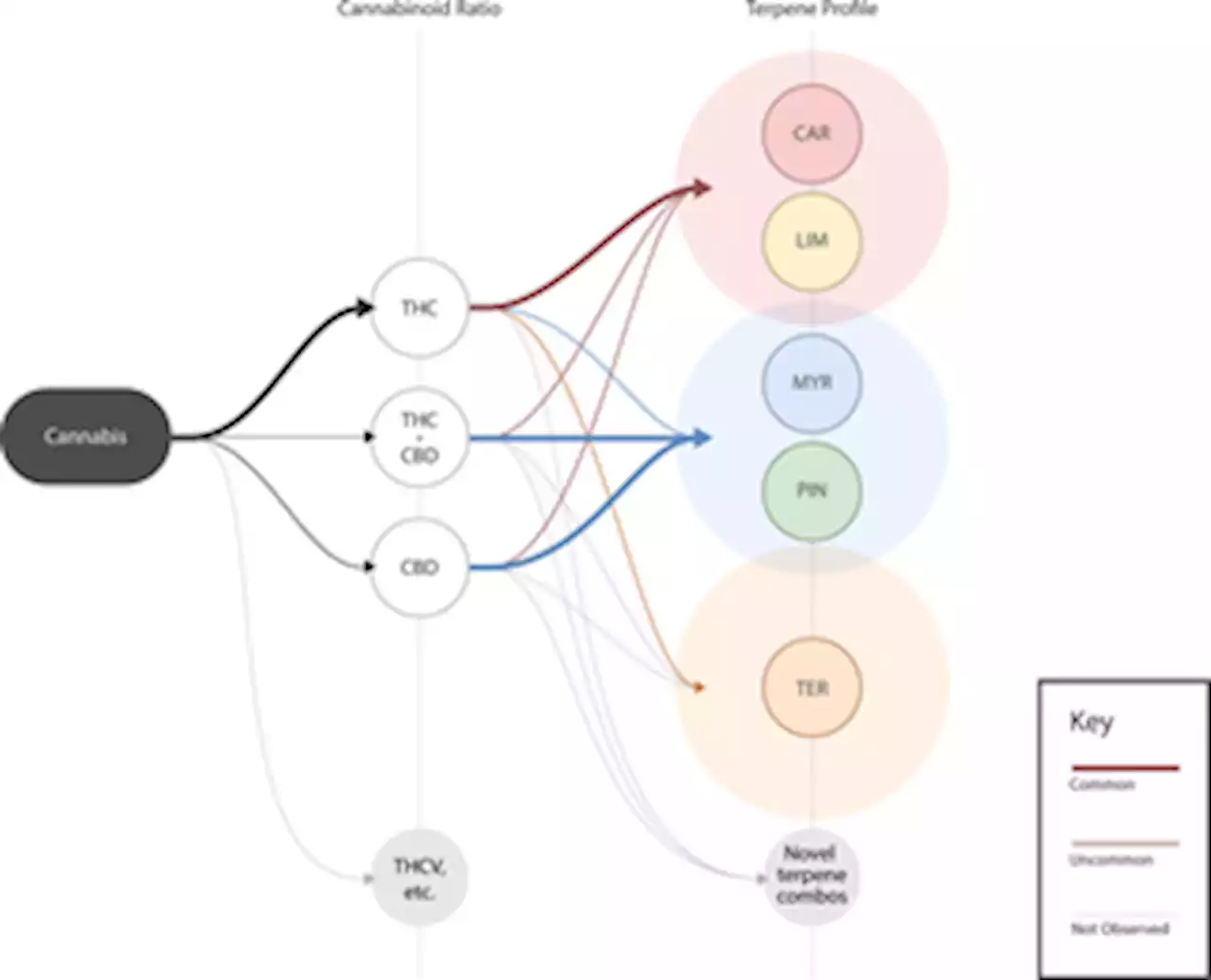
To illustrate a simple terpene profile, we ran k-means clustering on the product-level dataset. α- and β-pinene were summed together. The normalized terpene values and total THC, CBD, and CBG values from the THC-dominant product dataset were grouped by k-means cluster label and averaged. Polar plots were constructed based on the average terpene profiles and limited to eight terpenes to help with visual legibility.
Cosine similarities were calculated for the terpene profiles of products for each strain name, then averaged to assign a mean similarity score to each product . A violin/box plot was created with these similarity scores, ordered by median value. The dashed line inrepresents the average similarity score one would expect if strain names were randomly assigned, obtained by running a bootstrap simulation where strain names were shuffled across the product IDs.
A UMAP embedding was run on the normalized terpene data of the entire THC-dominant product dataset and color coded by k-means cluster label, k=3. The parameters for number of components and number of neighbors were specified as 2 and 15, respectively.Using the THC-dominant product dataset with k-means clustering , a UMAP embedding was run on the normalized terpene data and color coded by Indica/Sativa/Hybrid labels.
Excluding products without an associated Indica/Sativa/Hybrid label, the percentage of Indica/Sativa/Hybrid labels for products was found for each k-means cluster label. Chi-squared tests were calculated comparing these percentages with the overall percentages. Statistical significance was evaluated after using the Bonferroni correction for three multiple comparisons., the most frequent k-means cluster label was identified for each strain name.